RedPwn CTF 2019

Well to get started, I want to give you a glimpse of my experience with the CTF.
The Redpwn Organizers really did an awesome job in creating the challenges.
The quality of the challenges was awesome. Difficulty level was also mediumish.
It was a 3 day CTF and new challenges were updated timely.
The site got really slow once but that’s pretty common nowadays with the CTFd platform. XD
So after the 3 days long journey my team got the 8th position.
And in today’s post we’ll be discussing some forensic challenges only. I found these challenges worth a writeup and also I enjoyed them solving.
Some Quick Links
RedpwnGetsBamboozled
Dedication
Skywriting
RedpwnGetsBamboozled
Task Description :
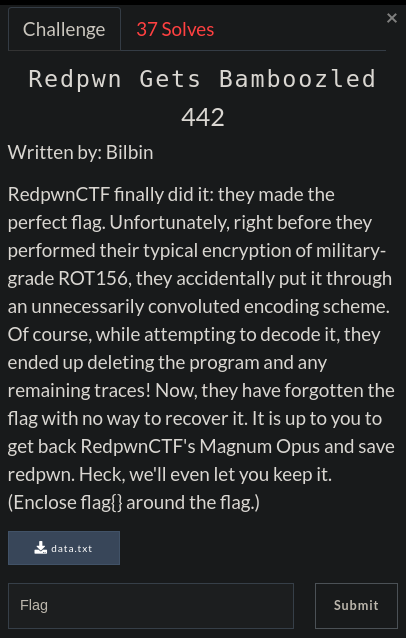
We were given just a txt file.
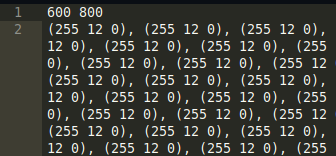
Ahhh! We can quickly observe that these are some (R, G, B) Values.
Also the initials of the Challenge Title is R, G, B XD
And at the beginning we get width and height as 600,800 respectively.
So its a basic python PIL task.
I just deleted the width and height values from the data.txt file and iterated all the RGB values and wrote them to a new Image.
1 | from PIL import Image |
Hmmm, I thought it would give us the flag but instead it gave us the following image.

So I tried various ways to decode it…
Approach with the image:
Once I tried stegsolve too LOL

After observing Red planes, I got some various patterns of dots that looked like braille but there were 8 dots in a column but we needed a multiple of 3 for decrypting if it would have been braille.
Also as one could easily observe that the dots are of different colours so I decided to change my strategy and moved towards the colour codes of the dots
I simply used the colour picker tool from GIMP and noted the color codes..
There were 10 different color codes in the image.
1 | 222222 cccccc dddddd 999999 444444 ffffff 555555 666666 333333 666666 |
I also tried sorting them by observing how frequently they appeared.
I tried taking their initials as all have single character.
And It came to me that what if the order is provided within the image itself as it can’t be so random dots.
So made a list of the Colour Code Initials ordering them as per the image..
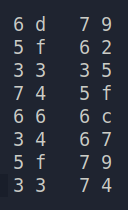
1 | 6d 79 5f 62 33 35 74 5f 66 6c 34 67 5f 79 33 74 |
And decoding it from hex to ascii we get the flag.
1 | flag{my_b35t_fl4g_y3t} |
Dedication
Task Description :
Ok so we got an encrypted zip file and another is a png.

But Wait, it’s not a png file but instead its a text file.

It also contains some RGB values but instead this time we are not provided with the width and height of the image but here we have different lines which can help us identify the height of the image and the no. of RGB values in a line help us identify the width of image.
So we start using our PIL ninja techniques.
1 | from PIL import Image |
This basic script just writes our pixel RGB values into an image of width and height of 400, 600 respectively. But you could notice that I’ve mirrored the image and then rotated it anticlockwise 90 degrees which was important to understand the text.
And I got the following image.

I quickly tried this as the password for the zip file and no wonder it worked. But to my surprise there was another zip with similar contents.
Ahhh, So this was also a scripting task. Obviously the basic approach which would help us automate the decryption of images was to use an OCR tool.
But this challenge screwed me for a while as I had a habit of using tesseract for every ocr task but this one was a nightmare with tesseract. It gave awful results. So I tried to switch over to some good ocr tool and I researched for a while and found a command-line tool known as GOCR
which gave somewhat accurate results.
1 | apt-get install gocr |
I wrote a bit messy script but still it works. XD
At first I tried to use ZipFile python library to extract the contents but it was ridiculously slow so I used the simple unzip command.
Also note that the password is not correct in every case as GOCR is not trained on this type of font or the colour values might matter so it’s not everytime perfect. So we’ve to enter some passwords manually.
To solve this situation and make it easy to enter password interactively while the script is running, we can just check the os.system() return code.
I learned that os.system() returns 0 if there is no error while executing the command. You can read more about it here. I also used Image.show() when the password is incorrect, which helps us in saving some time.
So I implemented all this and gave a seed value as the first directory named as jjofpbwvgk and put the text (fake png) and the image we got in it.
1 | from PIL import Image |
Ok if the script ran successfully you should get 1000 directories and our flag image residing in the 1000th directory.
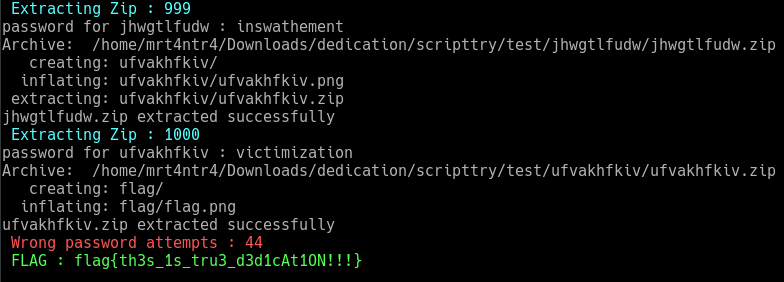
At the end, I’d say that it seriously needed some dedication LOL
Also If anyone knows about a more precise OCR tool, please let me know in the comments!!
Skywriting
Task Description :
By experience I knew that skywriting is a pretty common name for challenges so I first googled if there was any similar challenge from any previous ctf competition. And the first result I encountered was of PACTF 2018. The challenge was totally duplicated but we had to do it ourselves as flag was not the same as of PACTF. XD
You can read that writeup here.
I was being lazy so I searched more for a while to grab a better writeup which tells how to break the substitution cipher too.
I’ll just give a short summary of how I solved it taking the PACTF writeup as a reference as it’s not complete.
The key differences that the RedPwn CTF did made was renaming the gusty-garden-galaxy.wav files and modifying the flag so that we understand what we were doing.
After reading the writeup I installed the stegolsb tool.
1 | pip install stego-lsb |
So I used this tool to get about 5000 bytes of text from the gusty-garden-8.wav file which were enough for getting the flag.
I finally got some text from gusty-garden-galaxy-8.wav instead of gusty-garden-galaxy-6.wav.
1 | stegolsb wavsteg -r -i gusty-garden-galaxy-8.wav -o output.txt -b 5000 |
Now If your text editor or terminal supports unicode chars, it’ll display some text similar to the following.
1 | OMG WOW NO WAY |
This wasn’t gibberish, it was just some unicode characters.
As this was a substitution cipher, a little bit of frequency ananlysis is also required. So I turned to wikipedia to get some frequency analysis graphs of english alphabets.
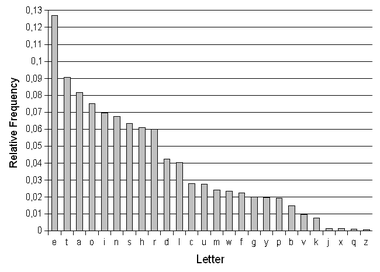
So I made a simple counter to get the no. of occurences of the unicode chars in the cipher.
1 | from collections import Counter |
1 | Counter({u' ': 548, u'\u064a': 361, u'\u062e': 295, u'\u2153': 234, u'\u03b9': 188, u'\u03b7': 186, u'\u03c7': 171, u'\u03b2': 166, u'\u2157': 163, u'\u827e': 156, u'\u0638': 128, u'\u4f0a': 92, u'\u0634': 90, u'\u03bb': 88, u'\u03b3': 86, u'\u0631': 66, u'\u03bc': 60, u'\u03b8': 57, u'\u2158': 44, u'-': 38, u',': 35, u'\n': 28, u'.': 28, u'\u5409': 24, u'\u0639': 23, u'\xbd': 22, u'\u5f00': 18, u'T': 9, u'\u2019': 8, u'!': 8, u'A': 8, u'G': 7, u'"': 6, u'E': 6, u'I': 5, u'O': 5, u'S': 5, u'R': 5, u'U': 5, u')': 4, u'(': 4, u'B': 4, u'\u2154': 4, u'M': 3, u'N': 3, u'W': 3, u';': 3, u'\u2014': 2, u"'": 2, u':': 2, u'\u03c0': 2, u'H': 2, u'1': 2, u'0': 1, u'8': 1, u'C': 1, u'F': 1, u'L': 1, u'P': 1, u'Y': 1, u'2': 1, u'9': 1}) |
Now comparing the counter values as it is sorted in the descending order I could replace them in the text with the following python script.
I started replacing the characters one by one and I used this tool to convert the unicode values to text online.
1 | infile = open('output_final.txt','r') |
Finally I got the decoded text as follows.
1 | OMG WOW NO WAY |
One thing to note here is, y and l are same in many places in the text. I don’t know maybe the organisers messed it up a bit..
Also they didn’t even read the decoded text which contains the string make sure to check out pactf 2019.
I also had trouble finding the flag as the link given was incomplete.
After some tinkering I found the flag on the link : https://tinyurl.com/tinyflaglink
I guessed tinyurl part from the PACTF writeup.
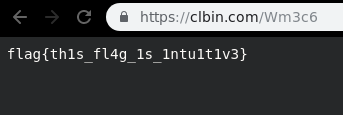
And finally we got our intuitive flag.

Thanks for Reading this writeup..
Subscribe to my Newsletter for more updates regarding CTFs.
Also Feedback is always appreciated.
It won’t take much time though.
And Keep Escalating the Privileges
Happy Hacking ;)