Nullcon HackIM CTF '20 [Year3000-RE]

So after such a long break I finally have something for you guys.
Also I’ll post something in every week from now on.
Spoiler.. Another writeup coming in a few days.
Today we’ll solve a challenge from Nullcon HackIM CTF which is organised every year.
I remember, previous year I was only able to solve 2 challenges XD
Challenge
One day when I came home at lunchtime I heard a funny noise Went out to the back yard to find out If it was one of those rowdy boys Stood there was my neighbor called Peter And a flux capacitor I guess there must be quite some entropy in a flux capacitor…
nc re.ctf.nullcon.net 1234
Download : year3000.tar.gz
Ahh We are given 3000 binaries which we have to crack and send the solution to the server which prompts with a random binary name.
But there’s a twist, the binaries are not of the similar architecture.. There are 64 bit and 32 bit versions mixed up.
But basically every binary accepts an input and calls another function to check it.
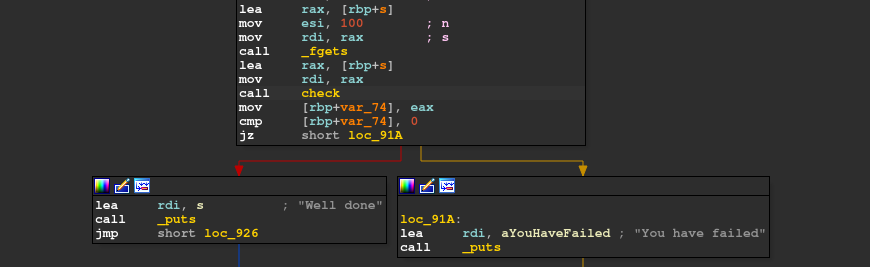
So we get to know that our input length is 100.
The Decompiled version of the check_fcn is :
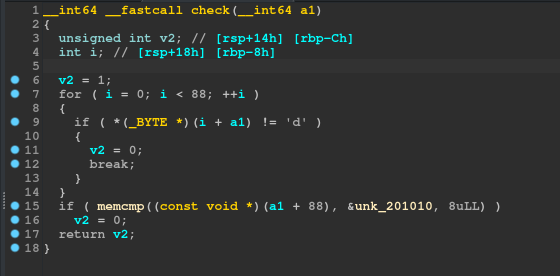
There’s a check for a single random byte from our input and then some last bytes of our input is compared with some predefined bytes in every binary.
My Approach
So long story short, I solved it using angr which is unintended. XD
I know it sounds a bit crazy but I didn’t had much time to look at this challenge as I wanted to spend my time on another challenge.
The server accepts our response within 7 secs else it’ll respond with too slow… so we can’t use angr with the server.
Also its only takes max 10-15 secs to solve a single binary using angr so I decided I’ll just run this script in 3-4 tabs and also asked my friend so that it gets solved in minimum time.
If I remember we were 5-6th solver of this challenge so it was pretty feasible.
I just wrote this as I didn’t find any other solution using angr for this problem after the ctf ended.
The main problem was how to reduce the time to crack a single binary.
Basically my idea was to run the script in multiple tabs and divide the binaries into chunks so that we get the solutions along with their filenames to individual csv files.
We can later join the individual files and use that to send our results to the server.
Solution
We begin by loading the binary as a project in angr and use the simplest entry state. I tried with a blank state but I was unlucky as there were differect architectures for binaries and there were some inconsistencies in addresses. And yeah I also tried to deal with that with a simple check case but nothing helped.
1 | proj = angr.Project(path) |
Now How can we determine the solution state?
Well angr has different options..
Like we can specify the addresses which we want to be reached by our solver and the other which we want to avoid.
But angr also supports boolean values in find and avoid arguments.
Since the binaries our PIE enabled and also architectures differ we can make use of their output to check if we have found a valid solution.
1 | def success(state): |
Now we just use our simulation manager to execute it symbolically and specify the return values and we are good to go.
1 | simulation.explore(find=success, avoid=failed) |
For further exploration you can visit the official docs.
Final Script
1 | import angr,claripy |
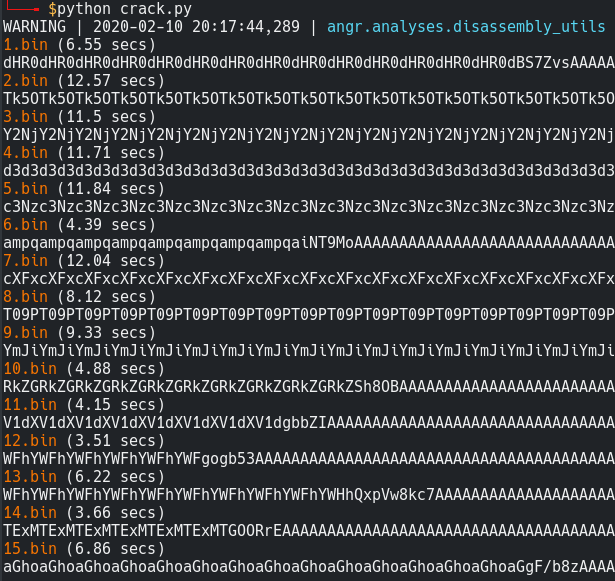
And also please don’t forget to use LAZY_SOLVES here as it takes half of the time in many cases.
The screenshot below depicts the time taken to generate a solution state without using lazy solves.
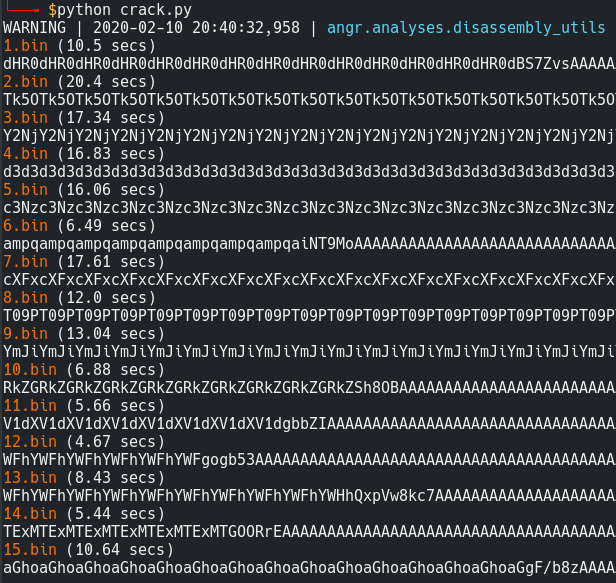
Finally It took around 3-4 hours to solve 3000 binaries.. phew
Then I just merged the csv files altogether and sent the solution for the required binary.
1 | from pwn import * |
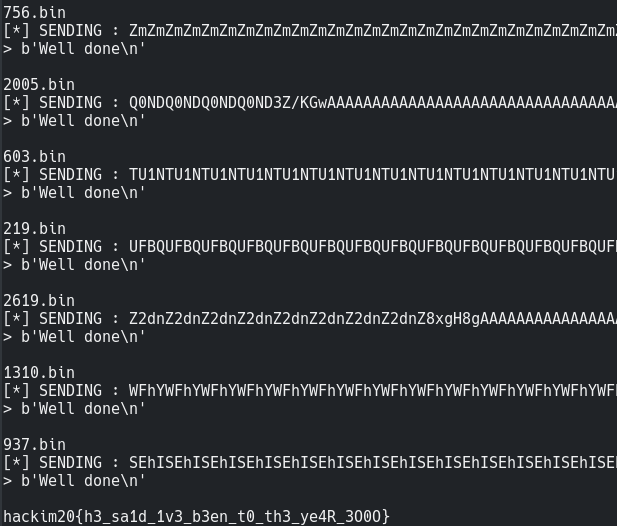
And thats how we travelled to the year 3000 XD

Also the challenge source was disclosed by the admins on github and you can try it locally using the Dockerfile.
Github Source year3000
I hope you guys liked it.
Feedbacks are appreciated !
See yall in next writeup :)